Hálózati réteg
A hálózati rétegnetwork layer Lényegében a kommunikációs alhálózatok működését vezérli. Nagyobb hálózatok esetén a keretek vevőtől a célba juttatása elvileg több útvonalon is lehetséges, feladat a bizonyos szempontból optimális útvonalnak a kiválasztása. Ez a tevékenység az útvonalválasztás (routing), és több megoldása lehetséges:
• a rendszer kialakításakor alakítjuk ki az útvonalakat,
• a kommunikáció kezdetén döntünk arról, hogy a teljes üzenet csomagjai milyen útvonalon jussanak el a rendeltetési helyükre,
• csomagonként változó, a hálózat vonalainak terhelését figyelembe vevő alternatív útvonalválasztás lehetséges.
Itt kell megoldani a túl sok csomag hálózatban való tartózkodása okozta torlódást, valamint különböző (heterogén) hálózatok összekapcsolását. More feladata a csomagok eljuttatása a forrástól a célig. A célig egy csomag valószínűleg több csomópontot is érint. Ehhez természetesen ismerni kell az átviteli hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More felépítését, azaz a topológiáját, és ki kell választania a valamilyen szempontból optimális útvonalat. Ha a forrás és a cél eltérő típusú hálózatokban vannak, a rétegA mai modern számítógép-hálózatok tervezését struktúrális módszerrel végzik, azaz a hálózat egyes részeit réteg-ekbe (layer) vagy más néven szint-ekbe (level) szervezik, amelyik mindegyike az előzőre épül. More feladata a hálózatok közti különbségből adódó problémák megoldása.
A megvalósításnál figyelembe kell venni azt a tényt, hogy alapvetően két eltérő hálózatszervezési módszer létezik: az egyik az összeköttetés alapú, a másik az összeköttetés mentes. Az összeköttetés alapú hálózatoknál az összeköttetést virtuális áramkörnek (VÁ) szokták nevezni. A forrás és a cél között felépült állandó úton vándorolnak a csomagok, de egy fizikai közeget egyszerre több virtuális kapcsolat használhat. Összeköttetés mentes hálózatokban az áramló csomagokat datagramoknak nevezik.
Virtuális áramkörök használatakor nem kell minden egyes csomagra forgalomirányítási döntést hozni. A forgalomszabályozás az összeköttetés létesítésének a része, vagyis kiválasztásra kerül a forrást és a célt összekötő útvonal, amelyen lezajlik az összeköttetés forgalma. Az ilyen módon felhasznált virtuális áramkörAz összeköttetés alapú hálózatoknál az összeköttetést virtuális áramkörnek (VÁ) szokták nevezni. A forrás és a cél között felépült állandó úton vándorolnak a csomagok, de egy fizikai közeget egyszerre több virtuális kapcsolat használhat. Virtuális áramkörök használatakor nem kell minden egyes csomagra forgalomszabályozási döntést hozni. A forgalomszabályozás az összeköttetés létesítésének a része, vagyis kiválasztásra kerül a forrást és a célt összekötő útvonal, amelyen lezajlik az összeköttetés forgalma. Az ilyen módon felhasznált virtuális áramkör az összeköttetés bontásakor megszűnik. A virtuális áramkörök kialakításához minden csomópontnak fenn kell tartani egy olyan táblázatot, amely bejegyzései a rajta keresztül haladó éppen használt virtuális áramkörök jellemzőit (honnan jött—hova megy) tartalmazzák, és az azonosításukra egy sorszámot használnak. Minden hálózaton keresztülhaladó csomagnak tartalmaznia kell az általa használt virtuális áramkör sorszámát. Amikor egy csomag megérkezik egy csomóponthoz, az tudja, hogy melyik vonalon jött, és mi az általa használt virtuális áramkörének sorszáma. A tárolt táblázatából ezek alapján ki tudja olvasni, hogy melyik csomópont felé kell továbbküldeni. More az összeköttetés bontásakor megszűnik. A virtuális áramkörök kialakításához minden csomópontnak fenn kell tartani egy olyan táblázatot, amely bejegyzései a rajta keresztül haladó éppen használt virtuális áramkörök jellemzőit (honnan jött – hova megy) tartalmazzák, és az azonosításukra egy sorszámot használnak. Minden hálózaton keresztülhaladó csomagnak tartalmaznia kell az általa használt virtuális áramkörAz összeköttetés alapú hálózatoknál az összeköttetést virtuális áramkörnek (VÁ) szokták nevezni. A forrás és a cél között felépült állandó úton vándorolnak a csomagok, de egy fizikai közeget egyszerre több virtuális kapcsolat használhat. Virtuális áramkörök használatakor nem kell minden egyes csomagra forgalomszabályozási döntést hozni. A forgalomszabályozás az összeköttetés létesítésének a része, vagyis kiválasztásra kerül a forrást és a célt összekötő útvonal, amelyen lezajlik az összeköttetés forgalma. Az ilyen módon felhasznált virtuális áramkör az összeköttetés bontásakor megszűnik. A virtuális áramkörök kialakításához minden csomópontnak fenn kell tartani egy olyan táblázatot, amely bejegyzései a rajta keresztül haladó éppen használt virtuális áramkörök jellemzőit (honnan jött—hova megy) tartalmazzák, és az azonosításukra egy sorszámot használnak. Minden hálózaton keresztülhaladó csomagnak tartalmaznia kell az általa használt virtuális áramkör sorszámát. Amikor egy csomag megérkezik egy csomóponthoz, az tudja, hogy melyik vonalon jött, és mi az általa használt virtuális áramkörének sorszáma. A tárolt táblázatából ezek alapján ki tudja olvasni, hogy melyik csomópont felé kell továbbküldeni. More sorszámát. Amikor egy csomag megérkezik egy csomóponthoz, az tudja, hogy melyik vonalon jött, és mi az általa használt virtuális áramkörének sorszáma. A tárolt táblázatából ezek alapján ki tudja olvasni, hogy melyik csomópont felé kell továbbküldeni. Összeköttetés mentes hálózatban elvileg minden egyes csomag különböző útvonalakat követhet, mivel a csomagok útválasztása egymástól független. Ilyenkor a csomagoknak tartalmazniuk kell mind a forrás, mind a cél teljes címét. A célcím alapján az adott irányba való küldésért a küldő IMP-n futó program felelős.
Milyen előnyei, illetve hátrányai vannak ezeknek a módszereknek?
Egyik mellett sem szól egyetlen döntő érv sem, amiAlternate Mark Inversion: - váltakozó 1 invertálás. A módszer nagyon hasonló az RZ módszerhez, de nullára szimmetrikus tápfeszültséget használ, így az egyenfeszültségű összetevője nulla. Minden 1-es-hez rendelt polaritás az előző 1-eshez rendelt ellentettje, a nulla szint jelöli a 0-át. Természetesen hosszú 0-s sorozatok esetén a szinkronizáció itt is problémás, de a bitbeszúrási módszer itt is használható. More alapján ki lehetne jelenteni, hogy melyik jobb. Például ha a csomagok nagyon rövidek, akkor a teljes célcím – amiAlternate Mark Inversion: - váltakozó 1 invertálás. A módszer nagyon hasonló az RZ módszerhez, de nullára szimmetrikus tápfeszültséget használ, így az egyenfeszültségű összetevője nulla. Minden 1-es-hez rendelt polaritás az előző 1-eshez rendelt ellentettje, a nulla szint jelöli a 0-át. Természetesen hosszú 0-s sorozatok esetén a szinkronizáció itt is problémás, de a bitbeszúrási módszer itt is használható. More a csomagküldéshez kell, általában jóval hosszabb mint a virtuális áramkört azonosítóEgy adott szolgáltatás igénybevételének jogát biztosító karaktersorozatok együttese. A leggyakrabban ez egy bejelentkezési névnek felel meg, amellyel egy adott felhasználó arra a számítógépre jelentkezhet be, ahol felhasználóként szerepel. Az azonosítót, amely általában a bejelentkezési nevet és a jelszót együtt jelenti, a felhasználó a hálózati szolgáltatójától kapja. Ennek birtokában a minket megillető erőforrásokat használhatjuk. More kód – csökkenti a hasznos adatátviteli sebességet. Azonban olyan rendszerekben, amelyekben tranzakciókat dolgoznak fel (pl. hitelkártya kódellenőrzés), a kapcsolat felépítésének majd lebontásának időtartama olyan időtöbbletet jelent, amiért nem érdemes ezt az összeköttetési módot használni. A legnagyobb gond a virtuális áramkörök biztonsága: egy virtuális áramköri táblázatokat tartalmazó IMPInterface Message Processor, azaz interfész üzenet feldolgozó. Az IMP-ek vagy a hoszt részei (pl. hálózati kártya és a programja) de sokszor valójában speciális számítógépek, amelyek a vonalak kapcsolását végzik, az a bemenetükre jutó adatot valamelyik meghatározott kimenetre kapcsolják (pl. routerek, hálózati átjárók). More gép meghibásodása miatt az összes rajta átmenő nyilvántartott virtuális áramkört újra kell építeni, és a félbeszakadt üzeneteket újra adni. Csomagkapcsolás esetén nem ilyen tragikus a helyzet, hiszen azokat a csomagokat kell újra adni, amelyek éppen továbbítás alatt voltak.
| Tárgy | DatagramA TCP/IP protokollban az információ datagramban terjed. A datagram (csomag) az üzenetben elküldött adatok összessége. Minden datagram a hálózatban egyedi módon terjed. Ezen csomagok továbbítására két protokoll, a TCP és az IP szolgál. A TCP (Transmission Control Protocol) végzi az üzenetek datagramokra darabolását, míg a másik oldalon az összerakást. Kezeli az esetleges elvesző csomagok újrakérését és a sorrendváltozást. Az IP (Internet Protocol) az egyedi datagramok továbbításáért felelős. More hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More | Virtuális áramkörös hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More |
|---|---|---|
| Áramkör létesítése | Nincs | Szükséges |
| Címzés | Minden csomagban forrás és célcím | Csak egy rövid virtuális áramkört azonosítóEgy adott szolgáltatás igénybevételének jogát biztosító karaktersorozatok együttese. A leggyakrabban ez egy bejelentkezési névnek felel meg, amellyel egy adott felhasználó arra a számítógépre jelentkezhet be, ahol felhasználóként szerepel. Az azonosítót, amely általában a bejelentkezési nevet és a jelszót együtt jelenti, a felhasználó a hálózati szolgáltatójától kapja. Ennek birtokában a minket megillető erőforrásokat használhatjuk. More cím |
| Állapotinformáció | Az alhálózat nem hordoz ilyen információt | Táblázatokban tárolt |
| ForgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More | A csomagok útvonala egymástól független | A VÁ létesítése meghatározza az útvonalat |
| Csomóponti hibák hatása | Csak az IMP-ben lévő csomagokra | Összes, az IMP-n átmenő VÁ meghal |
| Torlódásvezérlés | Nehéz megoldani | Könnyű, ha elegendő puffer van |
| Összetettség | A szállítási rétegben | A hálózati rétegben |
| Alkalmas | Összeköttetés-alapú és összeköttetés mentes szolgálathoz is | Összeköttetés-alapú szolgálathoz |
16. ábra: A hálózatszervezési módszerek összehasonlítása
Forgalomirányítás
A forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More (routingA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. Vonalkapcsolt hálózatoknál az útvonal kijelölése a hívás felépítésének fázisában történik. Csomagkapcsolt hálózatokban az útvonal kijelölése vagy minden csomagra egyedileg történik, vagy kialakít egy olyan útvonalat amelyen egy sorozat csomag megy át. Ezért a csomópontoknak ún. routingA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More táblákat kell tartalmazniuk, amelyekbe a velük kapcsolatban álló csomópontokra vonatkozó adatok (pl. távolság) be vannak jegyezve.
A forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More összetettségét alapvetően meghatározza a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More topológiája. Például egy csillaghálózatban, mivel a csillag központjában lévő csomóponton keresztül történik az adatátvitelKét vagy több eszköz közötti adatcsere. Az eszközök lehetnek számítógépek, perifériák, programok stb. Az adatátvitel fő jellemzője az adatátviteli sebesség, amely nagy mértékben függ az eszközök közötti kapcsolat, összeköttetés módjától, minőségétől. More, kizárólag ennek kell rendelkeznie a forgalomirányításhoz szükséges minden információval. Egy másik, ilyen szempontból egyszerű elrendezés a két irányú kommunikáció miatt duplán kialakított gyűrű, hiszen csomópontból csak két irányba lehet elküldeni a csomagokat, bár a két lehetséges út közül az egyik általában rövidebb a másiknál. Ezért vagy minden csomópont egy routingA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More táblát tartalmaz, amiben az összes többire vonatkozó távolság be van jegyezve, vagy a csomópontok számozási rendszere olyan, hogy a címe alapján a távolság meghatározható. Egy gyűrű esetén egyirányú pont-pont kapcsolat van, tehát a forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More a másik pontba való küldésre egyszerűsödik. Általában is elmondható, hogy szabályos elrendezések esetében általában könnyebb az optimális forgalomirányítási algoritmus kidolgozása. A legtöbb valóságos hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More lényegesen bonyolultabb topológiájú, szabálytalan szövevényes és sokszor állandóan változó szerkezettel rendelkezik. A forgalomirányító algoritmusok osztályozásának alapjául a következő négy irányítási főfunkciót tekinthetjük:
- vezérlésmód; (hogyan?)
- döntésfolyamat; (milyen esetben?)
- információ-karbantartó folyamat; (hálózati forgalmi ismeretek frissítése)
- továbbító eljárás (hogyan jut el a vezérlési információInformációnak nevezünk mindent, amit a rendelkezésünkre álló adatokból nyerünk. Az információ olyan tény, amelynek megismerésekor olyan tudásra teszünk szert, ami addig nem volt a birtokunkban. Az információ legkisebb egysége a bit. A számítástechnikában a programok is 1 bites információkból épülnek fel. More a csomópontokhoz?)
Ezek feladata a forgalomirányítási információk áramlásának szabályozása, a kerülő utak választékának kialakítása, az irányítási információk felújítása valamennyi csomópontban és az útvonalválasztás az adatcsomagok részére. A forgalomirányítási algoritmusoknak két osztálya van: az adaptív (alkalmazkodó), amely a hálózati forgalomhoz alkalmazkodik, és a determinisztikus (előre meghatározott), ahol az útvonal-választási döntéseket nem befolyásolják a pillanatnyi forgalom mért vagy becsült értékei. Ezek alapján alapvetően négy lehetséges vezérlésmód különböztethető meg:
- determinisztikus forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More; olyan rögzített eljárás, amelyet a változó feltételek nem befolyásolnak;
- elszigetelt adaptív forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More, amelynél minden csomópont hoz irányítási döntéseket, de csak helyi információk alapján;
- elosztott adaptív forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More, amelynél a csomópontok információt cserélnek azért, hogy az irányítási döntéseket a helyi és a kapott információkra együtt alapozhassák;
- központosított adaptív forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More, amelynél a csomópontok a helyi forgalmi információikat egy közös irányító központnak jelentik, amely erre válaszul forgalomirányítási utasításokat ad ki az egyes csomópontok részére.
Az említetteken kívül bevezethető még egy további forgalomirányítás-típus is, amelyet deltairányításnak neveznek. Ennél az eljárásnál a központi irányító egység munkáját a forgalomirányítási döntésekhez kizárólag abban az esetben használják fel, ha ezek a helyi információkra nem alapozhatók.
A legrövidebb út meghatározása
A forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More során két pont között meg kell találni a legoptimálisabb útvonalat, amely esetleg még egyéb csomópontokat tartalmazhat. Az optimális útvonal nem feltétlenül jelenti a fizikailag legrövidebb útvonalat, mivel számos egyéb tényező is befolyásolhatja az optimális választást: lehet például mértéknek a csomópont-átlépések számát tekinteni, lehet azt az időt, hogy mennyi idő alatt jut el a csomag, vagy a vonalhasználat költségeit. Az objektív mértékAz objektív mérték megállapításához lehet olyan teszteket futtatni az adott szakaszokon amely magadja az átlagos sorbaállási és átviteli késleltetési időt, és ezt tekinti a mértéknek. Általánosan egy adott szakasz mértékét a távolság, az adatátviteli sebesség, az átlagos forgalom, a kommunikációs költség, az átlagos sorhossz vagy más egyéb tényezők alapján határozzák meg. More megállapításához lehet olyan tesztet futtatni az adott szakaszokon amely megadja az átlagos sorba-állási és átviteli késleltetési időt, és ezt tekinti a mértéknek. Általánosan egy adott szakasz mértékét a távolság, az adatátviteli sebességAz adatátviteli sebesség két vagy több eszköz közötti adatátvitel gyorsaságát fejezi ki, az egy másodperc alatt átvitt bit-ek számával. Mennyisége a bit/secundum (bps). Lásd még: baud More, az átlagos forgalom, a kommunikációs költség, az átlagos sorhossz vagy más egyéb tényezők alapján határozzák meg.
Determinisztikus forgalomirányítás
Vannak olyan forgalomirányító módszerek, amelyeknél nincs szükség semmilyen forgalomirányítási táblára, a hálózati topológiaA hálózat összekapcsolási struktúráját jelenti. More ismeretére, minden csomópont autonóm módon, azonos algoritmus alapján dolgozik.
- A véletlen forgalomirányító eljárás alapján működő rendszerben a továbbítandó csomagot a csomópont egy ún. véletlen folyamat segítségével kiválasztott, az érkező vonaltól eltérő más vonalon küldi tovább. Mivel a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More által ilyen módon szállított csomagok véletlen bolyonganak, észszerűnek látszik, ha a csomagokhoz hozzárendeljük a mozgásuk során bejárt szakaszok számát és töröljük azokat a csomagokat, amelyek lépésszáma elér egy előre meghatározott értéket. Ez az eljárás nem garantálja a csomagok kézbesítését, de nagyon egyszerűen realizálható, és nem túl bonyolult hálózatokban jól működhet.
- Az elárasztásos forgalomirányító eljárás sem igényel semmi ismeretet a hálózatról. A csomópontok, mikor egy csomagot továbbítanak, a bejövő csomagot minden vonalra kiküldik, kivéve ahonnan érkezett. A lépések száma itt is korlátozva van. Jelentős érdeme a módszernek, hogy a csomag legalább egy példányban mindenképp a legrövidebb úton ér célba. Ez azonban jelentősen terheli a rendszert, mivel nagyszámú másolat (redundancia) van, és sok felesleges továbbítás történik. Az algoritmus rendkívül megbízható, és még megsérült rendszer esetén is működőképes. Katonai alkalmazások esetén előtérbe kerülhet a módszer, mert erősen sérült hálózatban (sok csomópontot kilőnek) is nagy a valószínűsége egy üzenet célba jutásának.
Adaptív algoritmusok
A probléma a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More elosztott jellegéből ered. A csomópontoknak ui. amikor irányítási döntéseket hoznak, olyan eseményeket kell figyelembe venniük, amelyek a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More távoli részében történtek, és amelyekről vagy egyáltalán nem rendelkeznek semmiféle információval, vagy a meglevő információjuk már időszerűtlen.
A csomagkapcsolt hálózatokban a forgalomirányítási információInformációnak nevezünk mindent, amit a rendelkezésünkre álló adatokból nyerünk. Az információ olyan tény, amelynek megismerésekor olyan tudásra teszünk szert, ami addig nem volt a birtokunkban. Az információ legkisebb egysége a bit. A számítástechnikában a programok is 1 bites információkból épülnek fel. More ugyanazon a közegen és ugyanolyan sebességgel halad, mint a felhasználói információInformációnak nevezünk mindent, amit a rendelkezésünkre álló adatokból nyerünk. Az információ olyan tény, amelynek megismerésekor olyan tudásra teszünk szert, ami addig nem volt a birtokunkban. Az információ legkisebb egysége a bit. A számítástechnikában a programok is 1 bites információkból épülnek fel. More. Nem volna értelme a csomagkapcsolt hálózatban az irányítási és egyéb vezérlő információkat egy külön, nagy adatátviteli sebességű rendszerben, a felhasználói forgalmat pedig kis sebességű vonalakon továbbítani. A csomagkapcsolt hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More szempontjából is jó lenne az egész hálózatra kiterjedő forgalomirányítási információInformációnak nevezünk mindent, amit a rendelkezésünkre álló adatokból nyerünk. Az információ olyan tény, amelynek megismerésekor olyan tudásra teszünk szert, ami addig nem volt a birtokunkban. Az információ legkisebb egysége a bit. A számítástechnikában a programok is 1 bites információkból épülnek fel. More azonnali elérhetősége. Bár a gyakorlatban ez megvalósíthatatlan, a szimulációs modellezés módszerével mégis analizálták az ilyen módon működő hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More elméleti teljesítőképességét. A szimuláció során minden egyes csomópont úgy hozta meg irányítási döntését, hogy ehhez a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More többi részéről is teljes körű és közvetlen áttekintése volt. Az irányító algoritmus – ismerve az összes többi csomóponton a sorok hosszát és minden egyes vonalon az áthaladó csomagok számát – az irányítás alatt álló csomagja részére azt a következő, optimális adatátviteli vonalat választotta ki, amelyen az áthaladva minimális késleltetési idővel érkezhetett célba. Ennek a szimulációs kísérletnek teljesen váratlanul az volt az eredménye, hogy itt az átlagos késleltetési idők nem voltak lényegesen kisebbek, mint a rögzített forgalomirányító eljárásnál, amelynél a forgalomirányítási táblákat a legrövidebb utakra állították be. Ennek az lehetett az oka, hogy bár a forgalomirányításA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More a pillanatnyilag lehető legpontosabb információn alapult, az időközben megváltozott forgalom miatt a döntés pillanatában optimális útvonal még a kérdéses csomag célba érkezése előtt már nem volt optimális. Még az is előfordulhat ennél a módszernél, hogy több csomópont egyszerre fedez fel egy gyengén terhelt hálózatrészt, és ezért valamennyi ide tereli a forgalmat és abban erős torlódást okoz. Ez szabályozástechnikai analógiával egy lengő rendszernek felel meg. Az ideális algoritmus sem tudja előre figyelembe venni a jövőben bekövetkező eseményeket. A szimuláció jól jellemzi a különböző, ténylegesen működő forgalomirányító algoritmusok egyik lehetséges nagy hátrányát; azt a tényt, hogy a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More egy bizonyos részéről a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More többi részei esetleg úgy értesülnek, hogy az pillanatnyilag alig van terhelve és tartalékkapacitással rendelkezik. Ha ezek a részek ugyanakkor éppen torlódással küszködnek, valamennyien egyszerre fognak arra törekedni, hogy ebbe az alig terhelt zónába tereljék a forgalmat, amivel ott még súlyosabb torlódást idézhetnek elő. A valóságos hálózatokban alkalmazott adaptív forgalomirányító eljárásoknak vagy a helyileg rendelkezésre álló információt (izolált adaptív irányítás), vagy a hálózatban terjesztett információt kell felhasználniuk.
Központi adaptív forgalomirányítás
Az eddig tárgyalt forgalomirányító algoritmusok vagy a helyileg rendelkezésre álló, vagy a szomszédos csomópontok között cserélt információt használják. A központosított adaptív forgalomirányításban minden egyes csomópont helyzetjelentést állít össze, és abban a folyó sorhosszakat, a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More elemeinek meghibásodásait stb. elküldi a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More forgalomirányító központjába (RCC = RoutingA forgalomirányítás (routing) feladata a a csomagok hatékony (gyors) eljuttatása az egyik csomópontból a másikba, illetve a csomagok útjának a kijelölése a forrástól a célállomásig. A hálózatot célszerű gráfként modellezni, ahol a csomópontok a csomagtovábbító IMP-k, és a csomópontokat összekötő élek az IMP-k közötti információs adattovábbító csatornák. A csomagok a hálózati vonalakon keresztül jutnak egy IMP-be, majd az valamilyen irányba továbbküldi a csomagokat. Mivel az ilyen hálózati csomópontok irányítási, továbbküldési kapacitása véges, elképzelhető a csomagok sorban állása a bemenő oldalon. A forgalomirányítási szemléletünket nagyon jól segíti az olyan analógia, ahol a hálózatot a közúti hálózat, míg a csomagokat az autók képviselik. A csomópontok pedig természetesen az útkereszteződések. More Controll Center). A központ ezek alapján átfogó képet alakít ki a hálózatról, és valamennyi forgalmi áramlat részére meg tudja határozni a legkedvezőbb útvonalat. Ezeket a legjobb utakat a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More csomópontjai forgalomirányítási táblák formájában kapják meg. A központnak szóló helyzetjelentéseket és a csomópontoknak szóló új irányítási táblákat szabályos időközözönként (szinkron üzemmódban) vagy csak jelentős változás hatására (aszinkron üzemmódban) küldik. Ha a szinkron üzemmódot választják, akkor az irányító algoritmus működtetése érdekében a hálózatban áramoltatott vezérlő információInformációnak nevezünk mindent, amit a rendelkezésünkre álló adatokból nyerünk. Az információ olyan tény, amelynek megismerésekor olyan tudásra teszünk szert, ami addig nem volt a birtokunkban. Az információ legkisebb egysége a bit. A számítástechnikában a programok is 1 bites információkból épülnek fel. More fantasztikus mennyiségűvé válhat. Különösen, ha a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More maga nagy, akkor a túlzott mértékű irányítási funkció jelentős többletterhelést okoz. Aszinkron üzemmódban viszont csak elfogadható mennyiségű vezérlő információInformációnak nevezünk mindent, amit a rendelkezésünkre álló adatokból nyerünk. Az információ olyan tény, amelynek megismerésekor olyan tudásra teszünk szert, ami addig nem volt a birtokunkban. Az információ legkisebb egysége a bit. A számítástechnikában a programok is 1 bites információkból épülnek fel. More áramlik a hálózatban. Azt várhatnánk, hogy a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More forgalomirányító központja az optimális utak kiválasztásához a lehető legjobban hasznosítja a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More kapacitását. Az elkerülhetetlen időkülönbségek miatt a csomópontokból elinduló állapotjelentések eleve késve érkeznek meg a központba és a távoli csomópontokból ez a késés már jelentős lehet. Megfordítva, miután a központ elvégezte a forgalomirányító funkció által igényelt tekintélyes idejű számításokat, további időhátrány származhat abból, hogy a csomópontok késve kapják a módosított forgalomirányítási táblákat. Így azután a központ olyan információk alapján dolgozik, amely részben már elavultak, és a csomópontok részére is olyan utasításokat ad ki, amelyek még inkább elavultak, amikor célba érnek.
Elszigetelt forgalomirányítás
Ilyenkor a forgalomirányítási döntéseket a helyi körülmények alapján hozza a csomópont. Egyszerű algoritmus az ún. “forró krumpli” algoritmus. Ennek az a lényege, hogy a beérkezett abba kimeneti sorba rakja, amely a legrövidebb, legrövidebb ideig “égeti a kezét”, gyorsan megszabadul tőle. Lényeges, hogy nem foglalkozik az irányokkal. Érdekes kiterjesztése az algoritmusnak, amikor enné a döntésnél az irányokhoz tartozó mértékeket is figyelembe veszi. Ez azt jelenti, hogy nem küldi automatikusan a legrövidebb sorba, hanem figyelembe veszi a kiválasztott sor mértékét is.
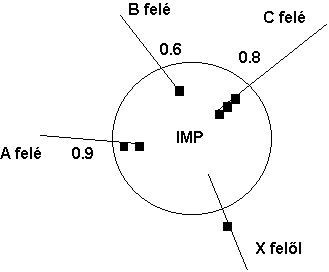
Például a 16. ábrán látható X jelű csomópont felől érkező csomag az eredeti algoritmus szerint B felé lenne elküldve. A módosított algoritmus szerint ez már nem biztos, hiszen a mértéke (jósága) csak 0.6, ezért talán jobb lehet az A irányt választani. A korrekt döntéshez kell egy a sorhosszt jellemző mérőszámot is választani (1-ha üres a sor, 0 — ha nagyon sok csomag van előtte) és így pl. a két szám szorzatának nagysága alapján hozni meg az irányra vonatkozó döntést.
Egy másik lehetséges algoritmus a fordított tanulás módszereAz elszigetelt forgalomirányítás egyik lehetséges algoritmusa a fordított tanulás módszere. A hálózatban minden csomópont egy csomagot indít el amely tartalmaz egy számlálót és az elindító azonosítóját. A számláló értéke minden csomóponton történő áthaladáskor megnöveli értékét egyel. Amikor egy csomópont (IMP) egy ilyen csomagot vesz, akkor ezt elolvasva tudja, hogy a csomagot küldő hány csomópontnyi távolságra van tőle. Természetesen az optimális út keresése érdekében, ha ugyanarra a távoli csomópontra egy kedvezőbb értéket kap (van rövidebb út is), akkor az előzőt eldobva ezt jegyzi magának. Ha azonban meghibásodás következik be, vagy az optimális útvonal valamelyik része túlterhelődik, akkor ezt az algoritmus nem veszi észre. Ezért célszerű időnként “mindent felejteni”, törölni a feljegyzéseket, hogy az ilyen változó körülményekre is működjön az algoritmus. More. A hálózatban minden csomópont egy csomagot indít el amely tartalmaz egy számlálót és az elindító azonosítóját. A számláló értéke minden csomóponton történő áthaladáskor megnöveli értékét egyel. Amikor egy csomópont (IMPInterface Message Processor, azaz interfész üzenet feldolgozó. Az IMP-ek vagy a hoszt részei (pl. hálózati kártya és a programja) de sokszor valójában speciális számítógépek, amelyek a vonalak kapcsolását végzik, az a bemenetükre jutó adatot valamelyik meghatározott kimenetre kapcsolják (pl. routerek, hálózati átjárók). More) egy ilyen csomagot vesz, akkor ezt elolvasva tudja, hogy a csomagot küldő hány csomópontnyi távolságra van tőle. Természetesen az optimális út keresése érdekében, ha ugyanarra a távoli csomópontra egy kedvezőbb értéket kap (van rövidebb út is), akkor az előzőt eldobva ezt jegyzi magának. Ha azonban meghibásodás következik be, vagy az optimális útvonal valamelyik része túlterhelődik, akkor ezt az algoritmus nem veszi észre. Ezért célszerű időnként “mindent felejteni”, törölni a feljegyzéseket, hogy az ilyen változó körülményekre is működjön az algoritmus.
Elosztott adaptív forgalomirányítás
A megvalósított hálózatokban mindeddig legnépszerűbb az elosztott adaptív forgalomirányító eljárás. Az algoritmus fő célkitűzése az adatforgalom részére a legkisebb késleltetéssel járó útvonalak keresése. E célból minden egyes csomópontban egy táblázatot hozunk létre, amely minden egyes célállomáshoz megadja a legkisebb késleltetésű útvonalat, s ezzel együtt a továbbításhoz szükséges idő legjobb becsült értékét. A hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More működésének kezdetén a késleltetések a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More topológiája alapján becsült értékek, később azonban, mihelyt a csomagok célba értek, a becsült késleltetési időket felváltják a hálózatban ténylegesen mért továbbítási idők. Az eredeti algoritmus szerint a késleltetési táblák adatait a szomszédos csomópontok rendszeresen megküldik egymásnak. Amikor a késleltetési táblákat megküldték, a csomópontok áttérnek a késéseket újraszámító fázisba, amelyben a saját sorhosszaikat és a szomszédos csomópontok által küldött késleltetési értékeket figyelembe veszik. A szomszédos csomópontok között a késleltetési táblák cseréje természetesen sok vezérlőcsomag továbbításával történik, amiAlternate Mark Inversion: - váltakozó 1 invertálás. A módszer nagyon hasonló az RZ módszerhez, de nullára szimmetrikus tápfeszültséget használ, így az egyenfeszültségű összetevője nulla. Minden 1-es-hez rendelt polaritás az előző 1-eshez rendelt ellentettje, a nulla szint jelöli a 0-át. Természetesen hosszú 0-s sorozatok esetén a szinkronizáció itt is problémás, de a bitbeszúrási módszer itt is használható. More jelentős többletterhelést ró a hálózatra. Ha a táblákat túl gyakran, pl. 2/3 másodpercenként tartják karban, a hálózati mérések azt mutatják, hogy a kis adatátviteli sebességű vonalak kapacitásának 50 százalékát a késleltetési táblák továbbításával járó forgalom foglalja le, és a lefoglalt kapacitás még a nagyobb sebességű vonalak esetén is észlelhető – bár kisebb – mértékű. A továbbított információról kimutatható, hogy az átvitt késleltetési táblák igen gyakran ugyanazt vagy majdnem ugyanazt az információt tartalmazzák, mint az őket megelőzők. A táblák ilyen, szinkron karbantartása helyett az aszinkron karbantartás a célravezetőbb. Ez utóbbi azt jelenti, hogy a csomópontoknak csak akkor kell továbbítaniuk a késleltetési táblákat, ha számottevő változást észlelnek a forgalom intenzitásában, vagy a hálózatÁltalában hálózaton sok eszköz összekapcsolt együttesét értjük. így egy számítógépes hálózatban, nem meglepő módon, számítógépek vannak egymással fizikai kapcsolatban. Ez alatt persze nem azt kell érteni, hogy minden gép minden másikkal közvetlenül össze van drótozva, hanem azt, hogy elvileg mindegyikük fel tud építeni kapcsolatot bármelyik másikkal. A közvetlen fizikai kapcsolat inkább a helyi hálózatokra jellemző. Mire jó (egyáltalán jó-e) a hálózat? Legfőképpen arra, hogy az összekapcsolódás révén az információ áramlása felgyorsul. Hasznos a hálózat abban a tekintetben is, hogy a számítógépek összekapcsolásával az eredetileg egyedül álló, gyengébb teljesítményű gépek együtt egy nagy teljesítményű rendszert alkotnak, amelynek segítségével különböző feladatok oldhatók meg. Mindezek pedig kifejezetten előnyös tulajdonságok. More elemeinek működési körülményeiben. A késleltetési táblák újraszámítására csak akkor kerül sor, ha jelentősebb helyi változás történt, vagy ha módosított késleltetési tábla érkezik valamelyik szomszédos csomóponttól.